Tetsu Matsukawa [English | Jpapanese]
Research Works on Person Re-Identification
Hierarchical Gaussian Descriptors
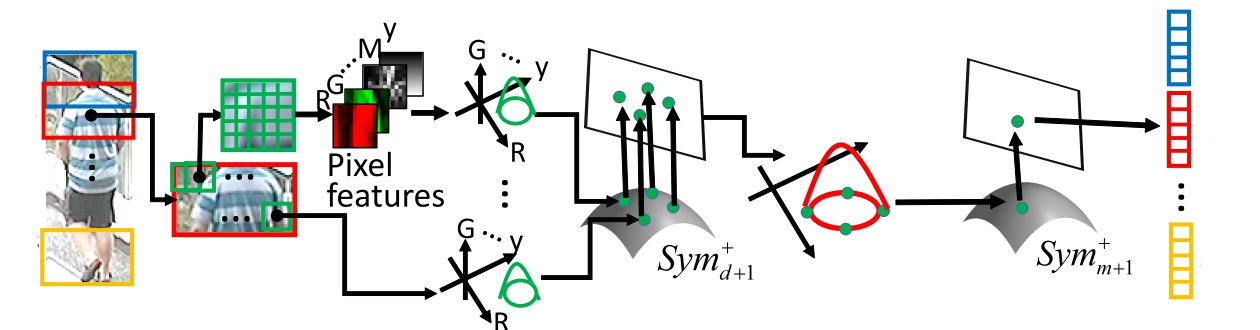 Describing the color and textural information of a person image is one of the most crucial aspects of person re-identification (re-id). Although a covariance descriptor has been successfully applied to person re-id, it loses the local structure of a region and mean information of pixel features, both of which tend to be the major discriminative information for person re-id.
In this paper, we present novel meta-descriptors based on a hierarchical Gaussian distribution of pixel features, in which both mean and covariance information are included in patch and region level descriptions.
More specifically, the region is modeled as a set of multiple Gaussian distributions, each of which represents the appearance of a local patch. The characteristics of the set of Gaussian distributions are again described by another Gaussian distribution.
Because the space of Gaussian distribution is not a linear space, we embed the parameters of the distribution into a point of Symmetric Positive Definite (SPD) matrix manifold in both steps.
We show, for the first time, that normalizing the scale of the SPD matrix enhances the hierarchical feature representation on this manifold. Additionally, we develop feature norm normalization methods with the ability to alleviate the biased trends that exist on the SPD matrix descriptors. The experimental results conducted on five public datasets indicate the effectiveness of the proposed descriptors and the two types of normalizations.
Describing the color and textural information of a person image is one of the most crucial aspects of person re-identification (re-id). Although a covariance descriptor has been successfully applied to person re-id, it loses the local structure of a region and mean information of pixel features, both of which tend to be the major discriminative information for person re-id.
In this paper, we present novel meta-descriptors based on a hierarchical Gaussian distribution of pixel features, in which both mean and covariance information are included in patch and region level descriptions.
More specifically, the region is modeled as a set of multiple Gaussian distributions, each of which represents the appearance of a local patch. The characteristics of the set of Gaussian distributions are again described by another Gaussian distribution.
Because the space of Gaussian distribution is not a linear space, we embed the parameters of the distribution into a point of Symmetric Positive Definite (SPD) matrix manifold in both steps.
We show, for the first time, that normalizing the scale of the SPD matrix enhances the hierarchical feature representation on this manifold. Additionally, we develop feature norm normalization methods with the ability to alleviate the biased trends that exist on the SPD matrix descriptors. The experimental results conducted on five public datasets indicate the effectiveness of the proposed descriptors and the two types of normalizations.
Resources [PAMI'19]
- Matlab code: ReID_HGDs_v1.0.zip
- Extracted features: HGDs_VIPeR.7z HGDs_GRID.7z HGDs_CUHK01.7z HGDs_CUHK03.7z HGDs_Market-1501.7z
- Matlab code: ReID_GOG_v1.02.zip
- Extracted features: GOG_VIPeR.zip GOG_CUHK01.zip GOG_PRID450S.zip GOG_GRID.zip GOG_CUHK03labeled.zip GOG_CUHK03detected.zip
- CMC curves: CMCs_GOG.zip (including VIPeR, PRID450S, GRID, CUHK01, CUHK03 datasets)
- Tetsu Matsukawa, Takahiro Okabe, Einoshin Suzuki, Yoichi Sato
Hierarchical Gaussian Descriptors with Application to Person Re-Identification
IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), vol.PP, no.99, p.1-14, 2019
[paper][appendix] - Tetsu Matsukawa, Takahiro Okabe, Einoshin Suzuki, Yoichi Sato
Hierarchical Gaussian Descriptor for Person Re-Identification
in Proceedings of IEEE Conference on Computer Vision and Pattern Recognition (CVPR2016), pp.1363--1372, 2016
[paper][supp][poster][slide]
CNN Features Learned from Combination of Attributes
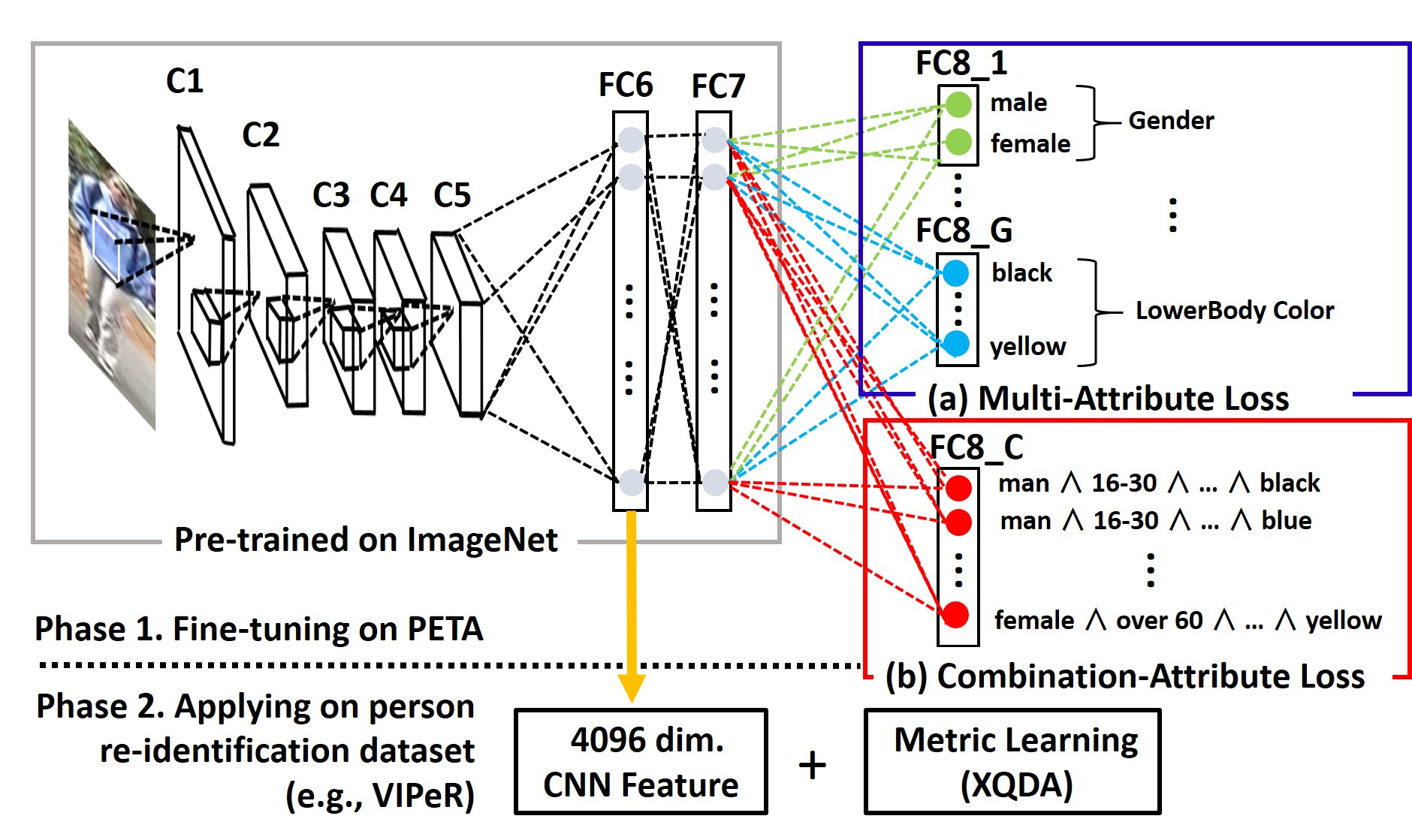 This paper presents fine-tuned CNN features for person re-identification.
Recently, features extracted from top layers of pre-trained Convolutional Neural Network (CNN) on a large annotated dataset, e.g., ImageNet, have been proven to be strong off-the-shelf descriptors for various recognition tasks. However, large disparity among the pre-trained task, i.e., ImageNet classification, and the target task, i.e., person image matching, limits performances of the CNN features for person re-identification. In this paper, we improve the CNN features by conducting a fine-tuning on a pedestrian attribute dataset. In addition to the classification loss for multiple pedestrian attribute labels, we propose new labels by combining different attribute labels and use them for an additional classification loss function. The combination attribute loss forces CNN to distinguish more person specific information, yielding more discriminative features.
After extracting features from the learned CNN, we apply conventional metric learning on a target re-identification dataset for further increasing discriminative power. Experimental results on four challenging person re-identification datasets demonstrate the effectiveness of the proposed features.
This paper presents fine-tuned CNN features for person re-identification.
Recently, features extracted from top layers of pre-trained Convolutional Neural Network (CNN) on a large annotated dataset, e.g., ImageNet, have been proven to be strong off-the-shelf descriptors for various recognition tasks. However, large disparity among the pre-trained task, i.e., ImageNet classification, and the target task, i.e., person image matching, limits performances of the CNN features for person re-identification. In this paper, we improve the CNN features by conducting a fine-tuning on a pedestrian attribute dataset. In addition to the classification loss for multiple pedestrian attribute labels, we propose new labels by combining different attribute labels and use them for an additional classification loss function. The combination attribute loss forces CNN to distinguish more person specific information, yielding more discriminative features.
After extracting features from the learned CNN, we apply conventional metric learning on a target re-identification dataset for further increasing discriminative power. Experimental results on four challenging person re-identification datasets demonstrate the effectiveness of the proposed features.
Download
- Extracted features: features_FTCNN.zip (including VIPeR, CUHK01, PRID450S, GRID datasets)
- CMC curves: CMCs_FTCNN.zip (including VIPeR, CUHK01, PRID450S, GRID datasets)
- Tetsu Matsukawa, Einoshin Suzuki,
Person Re-Identification Using CNN Features Learned from Combination of Attributes
in Proceedings of International Conference and Pattern Recognition (ICPR2016), pp.2429--2434, 2016
[paper][slide]
Discriminative Pooling of Convolutional Features
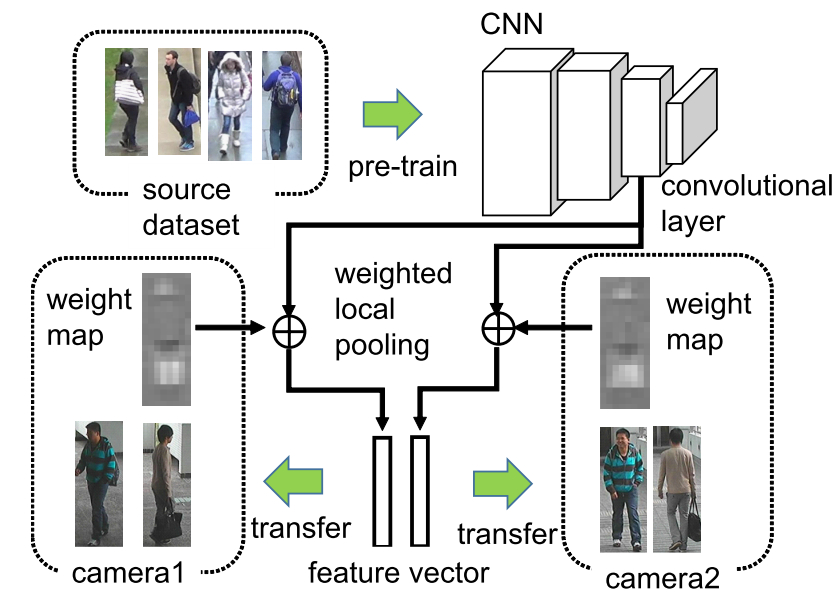 Modern Convolutional Neural Networks~(CNNs) have been improving the accuracy of person re-identification (re-id) using a large number of training samples.
Such a re-id system suffers from a lack of training samples for deployment to practical security applications. To address this problem, we focus on the approach that transfers features of a CNN pre-trained on a large-scale person re-id dataset to a small-scale dataset. Most of the existing CNN feature transfer methods use the features of fully connected layers that entangle locally pooled features of different spatial locations on an image.
Unfortunately, due to the difference of view angles and the bias of walking directions of the persons, each camera view in a dataset has a unique spatial property in the person image, which reduces the generality of the local pooling for different cameras/datasets.
To account for the camera- and dataset-specific spatial bias, we propose a method to learn camera and dataset-specific position weight maps for discriminative local pooling of convolutional features.
Our experiments on four public datasets confirm the effectiveness of the proposed feature transfer with a small number of training samples in the target datasets.
Modern Convolutional Neural Networks~(CNNs) have been improving the accuracy of person re-identification (re-id) using a large number of training samples.
Such a re-id system suffers from a lack of training samples for deployment to practical security applications. To address this problem, we focus on the approach that transfers features of a CNN pre-trained on a large-scale person re-id dataset to a small-scale dataset. Most of the existing CNN feature transfer methods use the features of fully connected layers that entangle locally pooled features of different spatial locations on an image.
Unfortunately, due to the difference of view angles and the bias of walking directions of the persons, each camera view in a dataset has a unique spatial property in the person image, which reduces the generality of the local pooling for different cameras/datasets.
To account for the camera- and dataset-specific spatial bias, we propose a method to learn camera and dataset-specific position weight maps for discriminative local pooling of convolutional features.
Our experiments on four public datasets confirm the effectiveness of the proposed feature transfer with a small number of training samples in the target datasets.
Publication
-
Tetsu Matsukawa<, Einoshin Suzuki
Convolutional Feature Transfer via Camera-specific Discrimative Pooling for Person Re-Identification
in Proceedings of 25th International Conference on Pattern Recognition (ICPR2020), pp.8408-8415, 2021
-
Tetsu Matsukawa, Takahiro Okabe, Yoichi Sato
Person Re-Identification via Discriminative Accumulation of Local Features
in Proceedings of International Conference on Pattern Recognition (ICPR2014), pp.3975-3980, 2014
[pdf][slide] [CMCs-curves]
Kernelized Cross-view Quadratic Discriminant Analysis
In person re-identification, Keep It Simple and Straightforward MEtric (KISSME) is known as a practical distance metric learning method. Typically, kernelization improves the performance of metric learning methods. Nevertheless, deriving KISSME on a reproducing kernel Hilbert space is a non-trivial problem. Nyström method approximates the Hilbert space in low-dimensional Euclidean space, and the application of KISSME is straightforward, yet it fails to preserve discriminative information. To utilize KISSME in a discriminative subspace of the Hilbert space, we propose a kernel extension of Cross-view Discriminant Analysis (XQDA) which learns a discriminative low-dimensional subspace, and simultaneously KISSME in the learned subspace. We show with the standard kernel trick, the kernelized XQDA results in the case when the empirical kernel vector is used as the input of XQDA. Experimental results on benchmark datasets show the kernelized XQDA outperforms XQDA and Nyström-KISSME.
Download
- Matlab code: ReID_KXQDA_v1.0.zip
- Extracted features: Features_CUHK01.zip Features_market-1501_train.zip Features_market-1501_test.zip Features_market-1501_query.zip
-
Tetsu Matsukawa, Einoshin Suzuki
Kernelized Cross-view Quadratic Discriminant Analysis for Person Re-Identification
in Proceedings of 16th IAPR Conference on Machine Vision Applications (MVA2019), pp.1-5, 2019
[pdf]
Copyright (c) Tetsu Matsukawa, All Right Researved.